(updated 05/09/2011)
In the Organik project we’ve been using the noun-phrase extraction modules of OpenNLP toolkit to extract key concepts from text for doing Taxonomy Learning. OpenNLP comes with trained model files for English sentence detection, POS-tagging and either noun-phrase chunking or full parsing, and this works great.
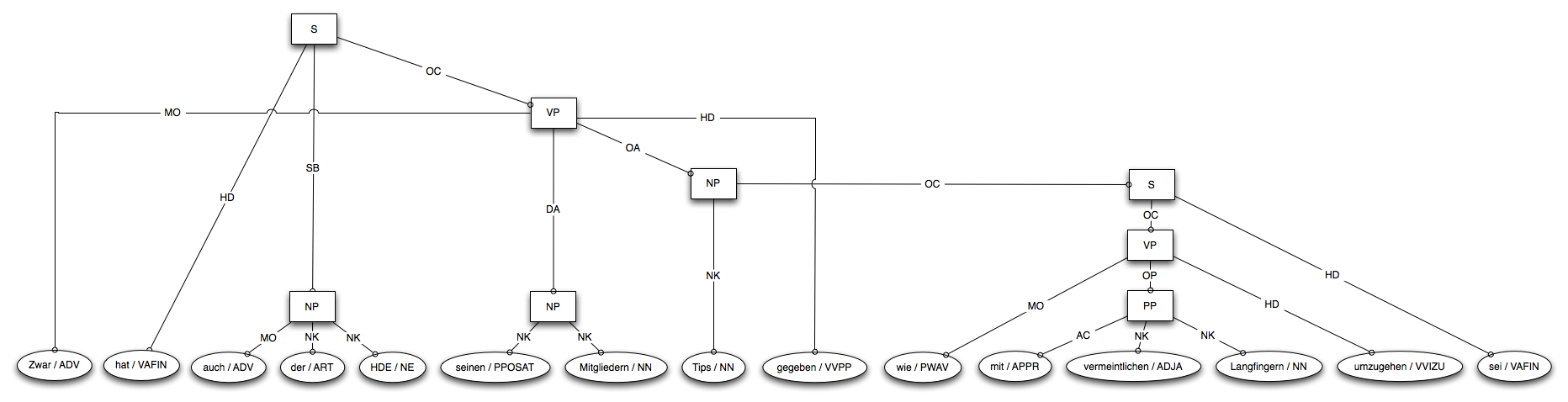
Of course in Organik we have some German partners who insist on using their awful german language [1] for everything – confusing us with their weird grammar. Finding a solution to this has been on my TODO list for about a year now. I had access to the Tiger Corpus of 50,000 German sentences marked up with POS-tags and syntactic structure. I have tried to use this for training a model for NP chunking, either using the OpenNLP MaxEnt model or with conditional random fields as implemented in FlexCRF. However, the models never performed better than around 60% precision and recall, and testing showed that this was really not enough. Returning to this problem now once again I have looked more closely at the input data, it turns out the syntactic structures used in the Tiger Corpus are quite detailed, containing far higher granularity of tag-types than what I need. For instance the structure for “Zwar hat auch der HDE seinen Mitgliedern Tips gegeben, wie mit vermeintlichen Langfingern umzugehen sei.” (click for readable picture):
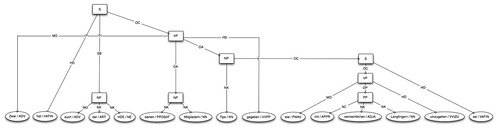
Here the entire “Tips […] wie mit vermeintlichen Langfingern umzugen sei”, is a noun-phrase. This (might) be linguistically correct, but it’s not very useful to me when I essentially want to do keyword extraction. Much more useful is the terms marked NK (Noun-Kernels), i.e. here “vermeintlichen Langfingern”. Another problem is that the tree is not continuous with regard to the original sentence, i.e. the word gegeben fits into the middle of the NP, but is not a part of it.
SO – I have preprocessed the entire corpus again, flattening the tree, taking the lowermost NK chain, or NP chunk as example. This gives me much shorter NPs in general, for which it is easier to learn a model AND the result is more useful in Organik. Running FlexCRF again on this data, splitting off a part of the data for testing, gives me a model with 94.03% F1-measure on the test data. This is quite comparable to what was achieved for English with FlexCRF in CRFChunker, for the WSJ corpus they report a F-Measure of 95%.
I cannot redistribute the corpus or training data, but here is the model as trained by FlexCRF for chunking: GermanNPChunkModel.tar.gz (17.7mb)
and for the POSTagging: GermanPOSTagModel.tar.gz (9.5mb)
Both are trained on 44,170 sentences, with about 900,000 words. The POSTagger was trained for 50 iterations, the Chunker for 100, both with 10% of the data used for testing.
In addition, here is a model file trained with OpenNLPs MaxEnt: OpenNLP_GermanChunk.bin.gz (5.2mb)
This was trained with the POS tags as generated by the German POStagger that ships with OpenNLP, and can be used with the OpenNLP tools like this:
java -cp $CP opennlp.tools.lang.german.SentenceDetector \
models/german/sentdetect/sentenceModel.bin.gz |
java -cp $CP opennlp.tools.lang.german.Tokenizer \
models/german/tokenizer/tokenModel.bin.gz |
java -cp $CP -Xmx100m opennlp.tools.lang.german.PosTagger \
models/german/postag/posModel.bin.gz |
java -cp $CP opennlp.tools.lang.english.TreebankChunker \
models/german/chunking/GermanChunk.bin.gz
That’s it. Let me know if you use it and it works for you!
Update 5/9/2011:
I have re-run the OpenNLP chunker with the most recent 1.5.1 version. The chunking model file format had changed, the updated file is here:
http://gromgull.net/2010/01/npchunking/OpenNLP_1.5.1-German-Chunker-TigerCorps07.zip. I did not redo the POS tagging, so if it changed from the old version the accuracy will suffer.
I’ve also put up the scripts I used to prepare this – starting with some corpus in the TIGER-XML treebank encoding format in tiger.xml and opennlp libraries in lib/:
# Convert XML to Flex
python tiger2flex.py tiger.xml > tiger.flex
# Reoplace POS tags with those OpenNLP produces
python retagflex.py tiger.flex > tiger.opennlp
# Learn chunking model
sh learnModel.sh tiger.opennlp chunkingmodel.zip
It’s a while since I wrote this code, so I am not 100% sure how it works any more, but it seems fine :)
[1] Completely unrelated, but to exercise your German parsing skills, check out some old newspaper articles. Die Zeit has their online archive available back to 1946, where you find sentence-gems like this: Zunächst waren wir geneigt, das geschaute Bild irgendwie umzurechnen auf materielle Werte, wir versuchten Arbeitskräfte und Zeit zu überschlagen, die nötig waren, um diese Wüste, die uns umgab, wieder neu gestalten zu können, herauszuführen aus diesem unfaßlichen Zustand der Zerstörung, überzuführen in eine Welt, die wir verstanden, in eine Welt,’ die uns bis dahin umgeben hatte. (ONE sentece!, from http://www.zeit.de/1946/01/Rueckkehr-nach-Deutschland)




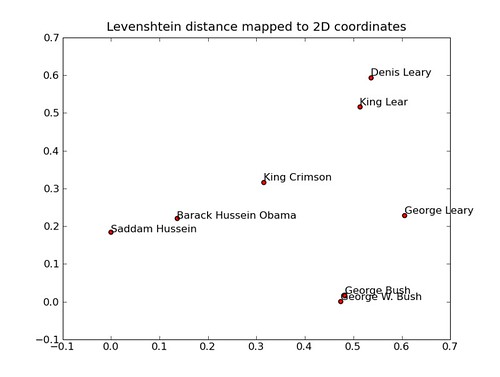
 is the distance (here simple 2d euclidean),
is the distance (here simple 2d euclidean),  is each domain,
is each domain,  is that domains position in the figure and
is that domains position in the figure and  is that domains feature vector. Normally it would be more natural to decrease the effect by the squared distance, but this gave less attractive results, and I ended up square-rooting it instead. The color is now simply on column of the resulting matrix normalised and mapped to a
is that domains feature vector. Normally it would be more natural to decrease the effect by the squared distance, but this gave less attractive results, and I ended up square-rooting it instead. The color is now simply on column of the resulting matrix normalised and mapped to a 

{kind=link}
{kind=link}