In the Organik project we’ve been using the noun-phrase extraction modules of OpenNLP toolkit to extract key concepts from text for doing Taxonomy Learning. OpenNLP comes with trained model files for English sentence detection, POS-tagging and either noun-phrase chunking or full parsing, and this works great.
Of course in Organik we have some German partners who insist on using their awful german language [1] for everything – confusing us with their weird grammar. Finding a solution to this has been on my TODO list for about a year now. I had access to the Tiger Corpus of 50,000 German sentences marked up with POS-tags and syntactic structure. I have tried to use this for training a model for NP chunking, either using the OpenNLP MaxEnt model or with conditional random fields as implemented in FlexCRF. However, the models never performed better than around 60% precision and recall, and testing showed that this was really not enough. Returning to this problem now once again I have looked more closely at the input data, it turns out the syntactic structures used in the Tiger Corpus are quite detailed, containing far higher granularity of tag-types than what I need. For instance the structure for “Zwar hat auch der HDE seinen Mitgliedern Tips gegeben, wie mit vermeintlichen Langfingern umzugehen sei.” (click for readable picture):
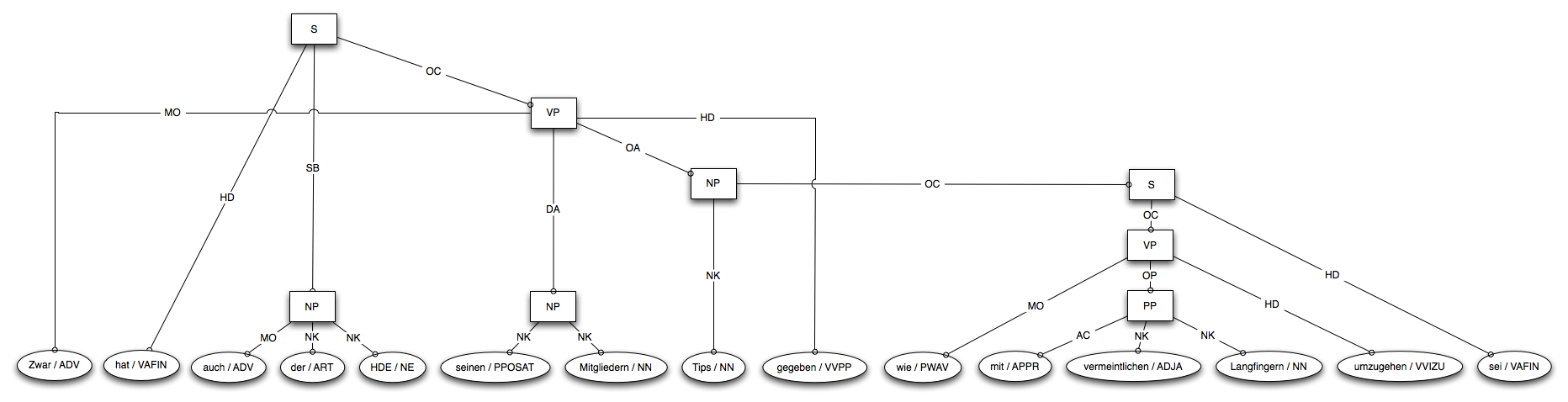
Here the entire “Tips […] wie mit vermeintlichen Langfingern umzugen sei”, is a noun-phrase. This (might) be linguistically correct, but it’s not very useful to me when I essentially want to do keyword extraction. Much more useful is the terms marked NK (Noun-Kernels), i.e. here “vermeintlichen Langfingern”. Another problem is that the tree is not continuous with regard to the original sentence, i.e. the word gegeben fits into the middle of the NP, but is not a part of it.
SO – I have preprocessed the entire corpus again, flattening the tree, taking the lowermost NK chain, or NP chunk as example. This gives me much shorter NPs in general, for which it is easier to learn a model AND the result is more useful in Organik. Running FlexCRF again on this data, splitting off a part of the data for testing, gives me a model with 94.03% F1-measure on the test data. This is quite comparable to what was achieved for English with FlexCRF in CRFChunker, for the WSJ corpus they report a F-Measure of 95%.
I cannot redistribute the corpus or training data, but here is the model as trained by FlexCRF for chunking: GermanNPChunkModel.tar.gz (17.7mb)
and for the POSTagging: GermanPOSTagModel.tar.gz (9.5mb)
Both are trained on 44,170 sentences, with about 900,000 words. The POSTagger was trained for 50 iterations, the Chunker for 100, both with 10% of the data used for testing.
In addition, here is a model file trained with OpenNLPs MaxEnt: OpenNLP_GermanChunk.bin.gz (5.2mb)
This was trained with the POS tags as generated by the German POStagger that ships with OpenNLP, and can be used with the OpenNLP tools like this:
java -cp $CP opennlp.tools.lang.german.SentenceDetector \
models/german/sentdetect/sentenceModel.bin.gz |
java -cp $CP opennlp.tools.lang.german.Tokenizer \
models/german/tokenizer/tokenModel.bin.gz |
java -cp $CP -Xmx100m opennlp.tools.lang.german.PosTagger \
models/german/postag/posModel.bin.gz |
java -cp $CP opennlp.tools.lang.english.TreebankChunker \
models/german/chunking/GermanChunk.bin.gz
That’s it. Let me know if you use it and it works for you!
Update 5/9/2011:
I have re-run the OpenNLP chunker with the most recent 1.5.1 version. The chunking model file format had changed, the updated file is here:
http://gromgull.net/2010/01/npchunking/OpenNLP_1.5.1-German-Chunker-TigerCorps07.zip. I did not redo the POS tagging, so if it changed from the old version the accuracy will suffer.
I’ve also put up the scripts I used to prepare this – starting with some corpus in the TIGER-XML treebank encoding format in tiger.xml and opennlp libraries in lib/:
# Convert XML to Flex python tiger2flex.py tiger.xml > tiger.flex # Reoplace POS tags with those OpenNLP produces python retagflex.py tiger.flex > tiger.opennlp # Learn chunking model sh learnModel.sh tiger.opennlp chunkingmodel.zip
It’s a while since I wrote this code, so I am not 100% sure how it works any more, but it seems fine :)
[1] Completely unrelated, but to exercise your German parsing skills, check out some old newspaper articles. Die Zeit has their online archive available back to 1946, where you find sentence-gems like this: Zunächst waren wir geneigt, das geschaute Bild irgendwie umzurechnen auf materielle Werte, wir versuchten Arbeitskräfte und Zeit zu überschlagen, die nötig waren, um diese Wüste, die uns umgab, wieder neu gestalten zu können, herauszuführen aus diesem unfaßlichen Zustand der Zerstörung, überzuführen in eine Welt, die wir verstanden, in eine Welt,’ die uns bis dahin umgeben hatte. (ONE sentece!, from http://www.zeit.de/1946/01/Rueckkehr-nach-Deutschland)
Banause!
Posted by Thomas Roth-Berghofer on January 14th, 2010.
[…] This post was mentioned on Twitter by Gunnar Grimnes and Andre Hagenbruch, Jochen Wersdörfer. Jochen Wersdörfer said: RT @gromgull: Noun-phrase chunking for German with OpenNLP: http://gromgull.net/blog/2010/01/noun-phrase-chunking-for-the-awful-german-l … […]
Posted by Tweets that mention (still) nothing clever — Noun-phrase Chunking for the Awful German Language -- Topsy.com on January 15th, 2010.
I just tried out your chunk model with OpenNLP 1.4, but it doesn’t seem to work. It only finds nominal phrases, nothing else. The tagger and tokenizer work well. Also, the english chunker works fine for me, so I can narrow down the problem to the german chunk model. Could you give it a try with OpenNLP yourself and look into this problem?
Posted by Stefan Oehme on April 29th, 2010.
Ah, just forget what I said. I read the HEADING of the text again. Stupid me ;)
Posted by Stefan Oehme on April 29th, 2010.
I am interested in training OpenNLP models (Sentence detection, POS Tagging, Chunking, Named entity detection etc.). I can’t find a training data set for English). Will you be able to point me to some data sets OR give me example(s) of data sets (in what format should they be?).
Thanks
Rohana
Posted by Rohana on May 26th, 2010.
Thanks for this very interesting and nice to read post! I am looking for an NP-chunker model for the current version of OpenNlp. Would you mind updating this post with a current model? Thanks, Hannes
Posted by Hannes on August 29th, 2011.
Hi Hannes, I am afraid I am not working with OpenNLP at the moment – how did the new versions change?
I’ll make a note of it – and perhaps I’ll find the time to re-run the learner from the old data!
Posted by gromgull on August 29th, 2011.
Hi Gromgull,
I was just wondering if you had the time to update the chunker to the current OpenNLP version and forgot to upload the version :-)
Cheers,
Daniel
Posted by Daniel on September 5th, 2011.
The new version encapsulates the maxent model in a zip package which contains additional meta-data. Would it be possible for you to share the code which generates the training data?
To re-train a model you would just need to download the current OpenNLP version and re-run the trainer.
Posted by Jörn on September 5th, 2011.
I retrained the model using 1.5.1, see update above.
I did not test it :)
Let me know if it works!
Posted by gromgull on September 5th, 2011.
I tested the model for 1.5.1 and it seems to work. Would you mind to contribute these training scripts back to OpenNLP? To do this you need to open a Jira issue and then simply attach your scripts (and mark the Apache License check box).
Posted by Jörn on September 20th, 2011.
Stefan Oehme wrote:
I just tried out your chunk model with OpenNLP 1.4, but it doesn’t seem to work. It only finds nominal phrases, nothing else.
I have the same problem. How did you solve the problem
Posted by Martin Baechtold on May 17th, 2012.
He re-read the post, in particular the subject :)
I stripped all other tags from the training data, and picked out only short NPs, as this was what I needed for a named entity detection toolchain. The corpus is too small (and german grammar too complicated :) for a full tagger from this data alone. I tried it, and the performance was quite bad.
Posted by gromgull on May 18th, 2012.
Do you also have a parser model file for German for the Apache OpenNLP parser? That would be great …
I am experimenting with sentiment and polarity analysis …
Posted by Manfred Alker on January 11th, 2013.
Hi Manfred, no parser model I am afraid, the Tiger Corpus I used is probably too small to train a parser (or even a full chunker).
You can try the Stanford Parser, they have models for German: http://nlp.stanford.edu/software/lex-parser.shtml
Posted by gromgull on January 12th, 2013.
Hi Gunner, thanks for the info! As a native German speaker, I am very amused anbout the “awful German language” … My deepest commiseration to all those who have to learn it as a foreign language … ;-)
Did you compare the CRF-Chunker (http://crfchunker.sourceforge.net/ ) with the Apache OpenNLP Chunker or tohers (Stanford?) for German (e.g., the f-measure)? Can you give me some tips which one to use?
Posted by Manfred Alker on January 16th, 2013.
Hi Gunner,
Great post. It was really helpfull for me. I’m developing rule based noun phrase chunker for german language(university project), and I used your script for proprocess tiger corpora. I also produced simple statistics about pos patterns which are noun phrases. What is interesting, almost 5000 noun phrases are just one word determiner like “die” or “das”. There’s a couple of similar examples like determiner and adjective or adverb or determiner and adverb which are noun phrases.
Posted by frankowp on October 6th, 2014.
Hi Gromgull,
I tried to use the chunker.model + manifest.properties (zipped to de-chunker.bin file and changed the manifest parameter “language” from ‘en’ to ‘de’) with Apache OpenNLP 1.5.2 but it failed with following error:
Exception in thread “main” java.lang.NullPointerException
at opennlp.tools.util.model.BaseModel.getManifestProperty(BaseModel.java:506)
at opennlp.tools.util.model.BaseModel.initializeFactory(BaseModel.java:248)
at opennlp.tools.util.model.BaseModel.loadModel(BaseModel.java:234)
at opennlp.tools.util.model.BaseModel.(BaseModel.java:176)
at opennlp.tools.chunker.ChunkerModel.(ChunkerModel.java:77)
at ChunkerExample.main(ChunkerExample.java:37)
Used code example from https://www.tutorialkart.com/opennlp/chunker-example-in-apache-opennlp/
Is your chunking model for 1.5.1 usable for version 1.5.2 ? If you, could you please provide the chunking model also for 1.5.2. Thank you.
Posted by Michael on October 19th, 2017.
Hey,
I have no idea how one would use a text based model with OpenNLP in 2019… and I haven’t found any resources on it online.
Can you (or someone else) help out?
Best regards!
Posted by Thomas on November 15th, 2019.